

Consultar registros de CloudFront
Consultar registros — Podemos permitir que Amazon CloudFront CDN exporte registros de acceso de distribución web (registros estándar / de acceso) a Amazon Simple Storage Service (S3).
¿Cómo consulta estos archivos?
- Servicio AWS Athena
- Databricks
Para consultar estos registros de CloudFront mediante el servicio AWS Athena y crear una base de datos y una tabla que apunten a la ubicación de S3. El siguiente ejemplo es de AWS.
CREATE DATABASE s3_access_logs_db; CREATE EXTERNAL TABLE `s3_access_logs_db.mybucket_logs`( `bucketowner` STRING, `bucket_name` STRING, `requestdatetime` STRING, `remoteip` STRING, `requester` STRING, `requestid` STRING, `operation` STRING, `key` STRING, `request_uri` STRING, `httpstatus` STRING, `errorcode` STRING, `bytessent` BIGINT, `objectsize` BIGINT, `totaltime` STRING, `turnaroundtime` STRING, `referrer` STRING, `useragent` STRING, `versionid` STRING, `hostid` STRING, `sigv` STRING, `ciphersuite` STRING, `authtype` STRING, `endpoint` STRING, `tlsversion` STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'input.regex'='([^ ]*) ([^ ]*) \\[(.*?)\\] ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) (-|[0-9]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) (\"[^\"]*\"|-) ([^ ]*)(?: ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*))?.*$') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://awsexamplebucket1-logs/prefix/'
Aquí hay muchas posibilidades de que reciba un error de Athena. Please reduce your request rate (reduzca la tasa de solicitudes) si hay una gran cantidad de archivos pequeños sin particiones que están en KB.

Para Databricks, necesitará un clúster con un nodo de tipo trabajador, por ejemplo, de 1 a 10 c5.4xlarge y un nodo de controlador que tenga la misma configuración que un trabajador. Databricks y una versión LTS dicen 7.3 con modo de clúster de alta concurrencia.
Se debe adjuntar un perfil de instancia de AWS a las instancias de Databricks que se permitirán en la política del bucket de s3. Más detalles aquí. Esto también debería resolver su problema de acceso en caso de que el bucket de S3 esté en otra cuenta de AWS.
{
"Version": "2012-10-17",
"Statement":
[
{
"Effect": "Allow",
"Principal":
{
"AWS":
[
"arn:aws:iam::89123:role/test-zone-s3-databricks"
]
},
"Action":
[
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::testbucket-cloudfront"
},
{
"Effect": "Allow",
"Principal":
{
"AWS":
[
"arn:aws:iam::89123:role/test-zone-s3-databricks"
]
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::testbucket-cloudfront/*"
}
]
}
Desde el lado de Databricks, tendrá que crear un cuaderno y probar la conexión al depósito s3:
%fs ls s3://testbucket-cloudfront/temp_folder/
Esto debería mostrarle los archivos presentes en el depósito s3 solo si desde el lado de acceso todo está bien.
La consulta de Athena también se puede utilizar en el cuaderno de Databricks para crear bases de datos y tablas.
¿Es este (in) famoso problema de archivo pequeño de chispa?
CloudFront descarga una gran cantidad de archivos pequeños, lo que presenta el famoso problema de archivos pequeños de Spark, donde se vuelve difícil para Spark procesar consultas sobre una gran cantidad de archivos pequeños.
Spark no está diseñado para acceder de manera eficiente a archivos pequeños: está diseñado principalmente para el acceso de transmisión de archivos grandes. La lectura de archivos pequeños normalmente provoca muchas búsquedas y muchos saltos de un nodo de datos a otro para recuperar cada archivo pequeño, todo lo cual es un patrón de acceso a datos ineficaz.
¿Cómo maneja estos pequeños archivos?
Puede utilizar el servicio DataSync AWS para copiar archivos por año, mes o fecha según sus requisitos en el nuevo bucket de S3 creando primero manualmente la estructura de directorio adecuada. Aquí excluya el prefijo de todos los archivos excepto el que desea copiar. Para ello, necesitará un rol que tenga acceso GET y PUT a ambos depósitos.
Otra forma es concatenar los archivos más pequeños y convertirlos en trozos más grandes de archivos, digamos 1 GB o 5 GB. Puede utilizar servicios como S3DistCp, o una función similar que tomará el archivo más pequeño, lo concatenará y transformará su formato a un formato Parquet.
Incluso puede utilizar trabajos por lotes de AWS S3 para copiar los archivos de un depósito a otro. Esto requerirá que generes un archivo manifest.json.
También puede pensar en la replicación desde el depósito de origen hasta el de destino, pero creo que esto no le ayudará a copiar los archivos de forma particionada y esto requerirá que se habilite el control de versiones.
¿Solucionando problemas del clúster de Databricks?
Puede haber problemas de immuta en caso de que su clúster de Databricks esté integrado con immuta. Immuta en lenguaje simple es una capa adicional de ACL en la parte superior de su clúster. Detalles pueden ser encontrados aqui.
com.immuta.spark.exceptions.ImmutaSecurityException: You may not access raw data directly.
Para ello, tendrá que crear un clúster incluido en la lista blanca de las capas de Immuta ACL.
El siguiente error py4j.securtiy.Py4JSecurityException también se puede solucionar si el acceso es bueno con el depósito S3.
![]()
En caso de que no pueda ejecutar las consultas como select * from db.table_name; o si el trabajo de Spark está en un estado de ejecución infinito, tendrá que cambiar la configuración del clúster.
- Modo de clúster de alta concurrencia a estándar.
Ingeniería ha incluido en la lista negra ciertas llamadas API que no pudieron verificar que sean seguras con clústeres de paso a través de credenciales / HC.
- Cambiar el tipo de instancia para los nodos de controlador y trabajador de
C5.4xlargeaR5.16xlarge.
Debido a muchas llamadas de red que estaban ocurriendo, pero no se notó mucho uso de la CPU.
- En la configuración de chispa del trabajo agregando un nuevo parámetro
spark.driver.maxResultSize 10g
Para corregir la excepción de chispa El tamaño total de los resultados serializados de 2514653 tareas (4.0 GiB) es mayor que spark.driver.maxResultSize 4.0 GiB.
- Es posible que vea un problema de Hadoop que se debe a un problema de acceso al depósito S3.
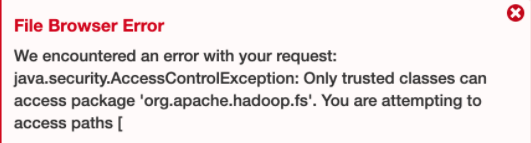
Espero que la información anterior le ayude a consultar los registros de CloudFront. No olvide compartirlo con sus colegas.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

await sin async en NodeJs

Quibi y lo que podemos aprender de su fracaso
