

¡Una mirada furtiva a AWS SageMaker!
SageMaker es uno de los servicios de aprendizaje automático más populares en AWS recientemente y también el que me llamó la atención.
En esta publicación, vamos a dar un vistazo de por qué AWS SageMaker es tan útil en el aprendizaje automático y nada más, ¡pronto llegarán más detallados y técnicos!
¿Qué es ML Pipeline y cómo podemos beneficiarnos de AWS SageMaker?
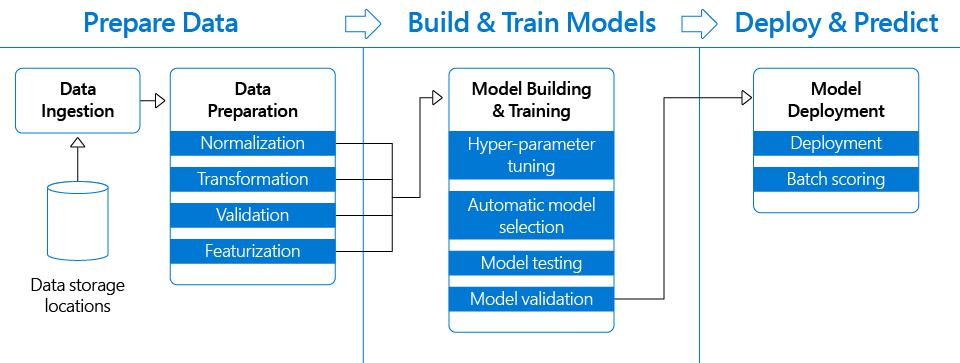
Una canalización de aprendizaje automático es una forma de codificar y automatizar el flujo de trabajo necesario para producir un modelo de aprendizaje automático. Las canalizaciones de aprendizaje automático constan de varios pasos secuenciales que hacen de todo, desde la extracción y el preprocesamiento de datos hasta el entrenamiento y la implementación de modelos.
Para los equipos de ciencia de datos, la canalización de producción debe ser el producto central, ya que se espera que construyan y usen las canalizaciones de datos, trabajen con almacenes de datos, entrenen y alojen modelos ML en la nube, etc. Encapsula todas las mejores prácticas aprendidas de producción un modelo de aprendizaje automático para el caso de uso de la organización y permite que el equipo se ejecute a escala. Ya sea que mantenga varios modelos en producción o admita un solo modelo que debe actualizarse con frecuencia, una canalización de aprendizaje automático de extremo a extremo es imprescindible.
Aquí, AWS SageMaker entra en escena y nos muestra su hermoso rostro sonriente en el momento en que luchamos por mantener nuestra canalización de ML personalizada.
AWS SageMaker proporciona Jupyter NoteBooks que ejecutan kernels R/Python con una instancia informática que podemos elegir según nuestros requisitos de ingeniería de datos bajo demanda.
Podemos visualizar, procesar, limpiar y transformar los datos en nuestros formularios requeridos usando los métodos tradicionales que usamos.
Podemos entrenar los modelos usando una instancia de computación diferente según la demanda de computación del modelo, como memoria optimizada o habilitada para GPU.

Otra gran ventaja de SageMaker es su diseño modular. Si prefiere capacitarse en otro lugar y solo usar SageMaker para la implementación, puede hacerlo. Si simplemente prefiere entrenar su modelo y usar su capacidad de ajuste de hiperparámetros, también puede hacerlo.
Ayuda con la creación de modelos, la formación y la implementación de modelos.
En pocas palabras, AWS SageMaker ha sido una gran oportunidad para la mayoría de los científicos de datos que querrían lograr una solución de aprendizaje automático verdaderamente integral. Se encarga de abstraer una tonelada de habilidades de desarrollo de software necesarias para realizar la tarea sin dejar de ser altamente eficaz, flexible y rentable. Lo que es más importante, lo ayuda a concentrarse en los experimentos básicos de ML y complementa las habilidades restantes necesarias con herramientas fáciles de abstraer similares a nuestro flujo de trabajo existente.
Nos vemos en otra publicación y comuníquese conmigo en LinkedIn o por correo electrónico o mediante los comentarios a continuación. ¡Todo lo mejor en su viaje de ML!

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Desarrollador senior: 5 características

API Gateway: Error al llamar función Lambda
