

Qué esperar al utilizar AWS Lambda
La implementación de soluciones de aprendizaje automático a menudo presenta desafíos imprevistos. Cuando los resultados del modelo están diseñados para servir como puntos de enlace de AWS Lambda, la solución está diseñada para ser compatible con SOA.
AWS Lambda es un servicio informático sin servidor proporcionado por Amazon para reducir la configuración de los servidores, el sistema operativo, la escalabilidad, etc.
En nuestras pruebas con puntos finales de Lambda para la canalización de inferencia del modelo ML, notamos que obteníamos diferentes tiempos de respuesta para la lógica de inferencia. Esto estaba afectando tanto el costo como la experiencia del usuario.
Entonces, tratamos de comprender la ejecución del servicio Lambda y cómo Lambda maneja las solicitudes.
Ciclo de vida lambda
Veamos el ciclo de vida de Lambda para comprender la latencia y cómo Lambda maneja las solicitudes:

Cuando el servicio de Lambda recibe una solicitud, el servicio primero prepara un entorno de ejecución:
- Código de descarga: extraiga el código del depósito s3 o la imagen de ECR si la función utiliza el embalaje del contenedor
- Create env: crea un entorno con memoria, tiempo de ejecución y configuración especificados
- Código de inicialización: código de inicialización fuera del controlador de Lambda (enlace a otros servicios de AWS, etc.)
- Ejecutar código de controlador: ejecuta el controlador y el servicio está listo para responder a las solicitudes
Inicio en frío: el tiempo que tarda el servicio en preparar la función y configurar el entorno.
El inicio en frío agrega latencia a la solicitud, pero AWS no cobra por este tiempo.
Los entornos de ejecución de Lambda manejan una solicitud a la vez. Una vez finalizada la invocación, el entorno de ejecución se conserva durante un período.
Si llega otra solicitud durante este período, el entorno se reutiliza para manejar la solicitud posterior. Las solicitudes manejadas durante este tiempo son solicitudes cálidas.
Los arranques en frío pueden ser un problema mayor en escenarios como:
- Tamaño de imagen/código grande (tiempo de descarga)
- Tamaño de modelo grande (tiempo para cargar e inicializar el modelo)
- Grandes requisitos de memoria
Patrones de invocación Lambda
Veamos cómo lambda maneja las solicitudes paralelas. Si las solicitudes llegan simultáneamente, el servicio se amplía y crea varios entornos de ejecución.
El inicio en frío ocurrirá para la primera invocación en el entorno lambda, ya que cada entorno se configura de forma independiente. Por lo tanto, cada solicitud experimenta un arranque en frío completo.
Por ejemplo, si API Gateway invoca Lambda seis veces simultáneamente, este crea seis entornos de ejecución. La duración total de cada invocación incluye un arranque en frío:

En función de cuántos servicios se estén ejecutando disponibles, el entorno de ejecución de Lambda existente recoge la solicitud posterior o se crea un nuevo entorno para atender la solicitud.
Por lo tanto, si API Gateway invoca a Lambda 6 veces de forma secuencial con un retraso entre cada invocación, los entornos de ejecución existentes se reutilizan si se completa la invocación anterior.
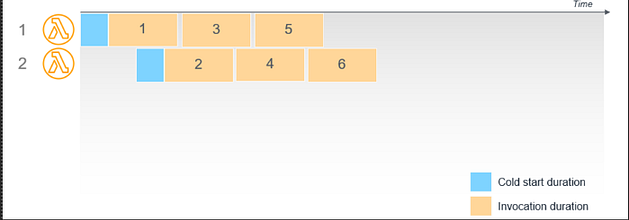
Nota: Normalmente, las primeras solicitudes tienen latencia adicional debido al inicio en frío, pero las solicitudes intermedias también pueden agregar latencia debido al patrón de invocación de Lambda mencionado anteriormente.
Observaciones experimentales
Creamos un script de python para invocar la lambda en diferentes intervalos de tiempo. El objetivo de esto era notar tiempos de respuesta para diferentes duraciones.
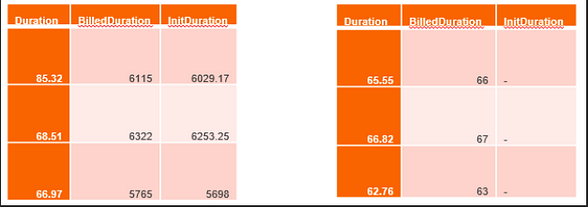
Observamos que algunas de las solicitudes se habían facturado por la duración de:
- 90 segundos (solicitudes de arranque en frío)
- 6–7 segundos con duración inicial (solicitudes de arranque en semifrío)
- 65 mseg (solicitudes cálidas, sin latencia adicional, la duración facturada y la duración son casi idénticas)

Dependiendo de cuánto tiempo esté inactivo el servicio desde la última solicitud atendida, el servicio comienza a desasignar los recursos comenzando por eliminar el entorno de ejecución (deshacer el paso 2 en la figura 1) y luego eliminar el código descargado (deshacer el paso 1 en la figura 1) .
Para las solicitudes semifrías, el servicio de Lambda debe volver a ejecutar el código descargado (en el caso de las imágenes Lambda del contenedor, la imagen está presente en la memoria y se vuelve a ejecutar). Este tiempo se menciona en la duración inicial.
Después de algunas pruebas, descubrimos que Lambda tiene una vida fija de 5 minutos, lo que significa que más allá de los 5 minutos, Lambda ya no se enciende. Por lo tanto, después de 5 minutos, Lambda debe inicializarse nuevamente. Entonces, las solicitudes que llegan dentro de los 5 minutos son cálidas, y después de un intervalo de 5 minutos, las solicitudes tienen una duración inicial.
Soluciones propuestas
Con base en nuestras observaciones, identificamos dos enfoques
1. Enfoque para mejorar el tiempo de respuesta del arranque en frío:
- Reducir el tamaño del contenedor: técnicas de cuantificación para reducir el tamaño del modelo, mantener dependencias mínimas y código en la imagen.
2. Enfoques para evitar la latencia de arranque en frío:
- Simultaneidad aprovisionada y reservada
- Uso de calentadores de funciones: mantenga la lambda caliente enviando periódicamente solicitudes ficticias
Conclusión
Para concluir, estamos tratando de comprender los comportamientos impredecibles de lambda y la ejecución del servicio lambda debido a los costos y la experiencia del usuario. Aquí mencionamos cómo el servicio maneja las solicitudes y nuestras observaciones.
Entre las soluciones propuestas, hemos implementado la optimización del modelo y reducido el tamaño del contenedor, otro compañero nuestro ha implementado la función calentadores ya que el requisito en su caso era mantener las funciones siempre disponibles.
Como conclusión clave de esta publicación, siempre debe intentar crear un paquete con dependencias mínimas y cuantificación para obtener los mejores tiempos de respuesta.
Gracias por llegar hasta aquí, si encuentras esto útil no olvides dejar un👍🏼y suscribirse para recibir más contenido.
Si le interesa, puede echar un vistazo a algunos de los otros artículos que he escrito recientemente sobre AWS y Laravel:

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Frameworks de desarrollo web más solicitados en 2021

Procesos secundarios en Nodejs
