

¿Cómo extraer datos web usando Node.js?
En este blog, descubriremos cómo utilizar Node.js y sus paquetes para extraer datos rápida y eficientemente para aplicaciones de una sola página. Nos ayudará a recopilar y utilizar datos importantes a los que no siempre se puede acceder mediante las API. Vamos a repasarlo.
Sugerencia: compartir y reutilizar módulos JS usando bit.dev
Utilice Bit para resumir componentes o módulos con toda la configuración y dependencias. Compártalos usando la nube de Bit, trabaje junto con el equipo y utilícelos en cualquier lugar.
¿Qué es la extracción de datos web?
La extracción de datos web es un método utilizado para extraer datos de sitios web con un script. El raspado de datos es una forma de automatizar la difícil tarea de copiar datos de diferentes sitios web.
En general, el web Scraping se realiza cuando los sitios web deseados no procesan la API para obtener datos. Algunos escenarios generales de raspado de datos incluyen:
- Extracción de correos electrónicos de diferentes sitios web para los clientes potenciales de ventas.
- Extracción de titulares de noticias de diferentes sitios web de noticias.
- Extracción de datos de productos de diferentes sitios de comercio electrónico.
¿Por qué requerimos web scraping mientras que los sitios de comercio electrónico exponen API (API de publicidad de productos) para obtener o recopilar datos de productos?
Los sitios de comercio electrónico solo descubren algunos de los datos del producto para obtenerlos a través de las API, por lo que el web scraping es una forma más eficiente de recopilar el máximo de datos del producto.
Los sitios web de comparación de productos normalmente realizan el raspado de datos. Incluso Google raspa y rastrea para indexar los resultados de búsqueda.
¿Qué querríamos?
Comenzar con el raspado de datos es fácil y se divide en dos partes fáciles:
- Extraer datos haciendo una solicitud HTTP
- Raspado de datos importantes a través del análisis de HTML DOM
Estaríamos utilizando Node.js para el raspado de datos. También utilizaríamos dos módulos npm de código abierto:
- Axios: es un cliente HTTP basado en promesas para navegador y node.js.
- Cheerio -Cheerio hace que sea fácil elegir, editar y ver los componentes DOM.
Puede obtener más información sobre la comparación de bibliotecas de solicitudes HTTP conocidas.
Consejo: no duplique el código común. Utilice herramientas como Bit para organizar, compartir y descubrir componentes para que las aplicaciones creen más rápido. Solo echa un vistazo.
Configuración
La configuración es muy fácil. Creamos una nueva carpeta y ejecutamos el comando dentro de la carpeta para crear un archivo package.json. Hagamos una receta para hacer la comida deliciosa.
Antes de comenzar a cocinar, obtengamos los ingredientes para la receta. Agregue Cheerio y Axios de npm como nuestras dependencias.
npm install axios cheerio
Luego, utilícelos en el archivo `index.js`
const axios = require('axios'); const cheerio = require('cheerio');
Hacer una solicitud
Después de recolectar todos los ingredientes, comencemos a cocinar. Estamos extrayendo datos de un sitio de HackerNews para el que tenemos que realizar la solicitud HTTP para obtener contenido del sitio web. Y ahí es donde los axios tienen un papel que desempeñar.
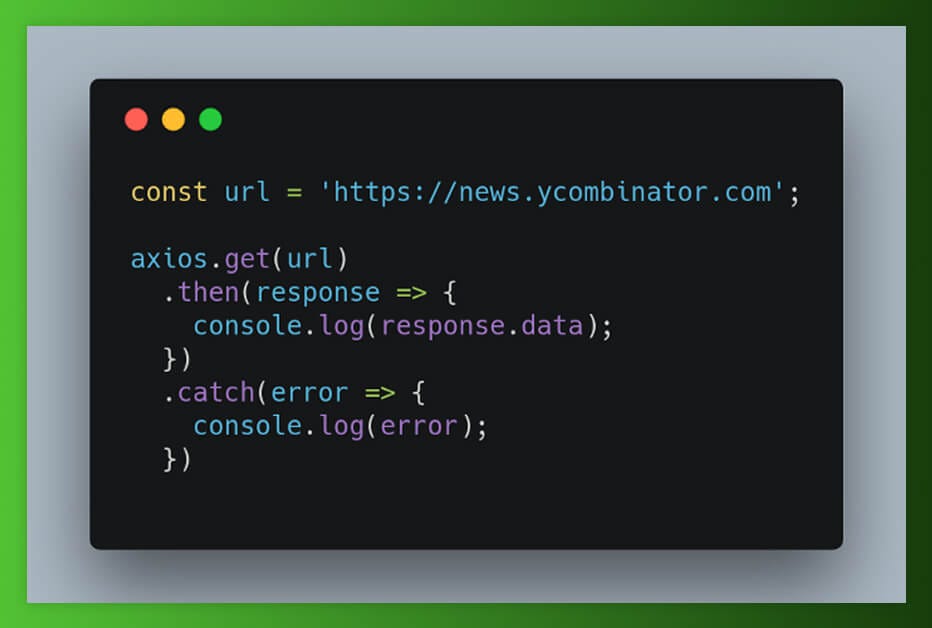
Nuestra respuesta aparecerá así:
<html op="news"> <head> <meta name="referrer" content="origin"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link rel="stylesheet" type="text/css" href="news.css?oq5SsJ3ZDmp6sivPZMMb"> <link rel="shortcut icon" href="favicon.ico"> <link rel="alternate" type="application/rss+xml" title="RSS" href="rss"> <title>Hacker News</title> </head> <body> <center> <table id="hnmain" border="0" cellpadding="0" cellspacing="0" width="85%" bgcolor="#f6f6ef"> . . . </body> <script type='text/javascript' src='hn.js?oq5SsJ3ZDmp6sivPZMMb'></script> </html>
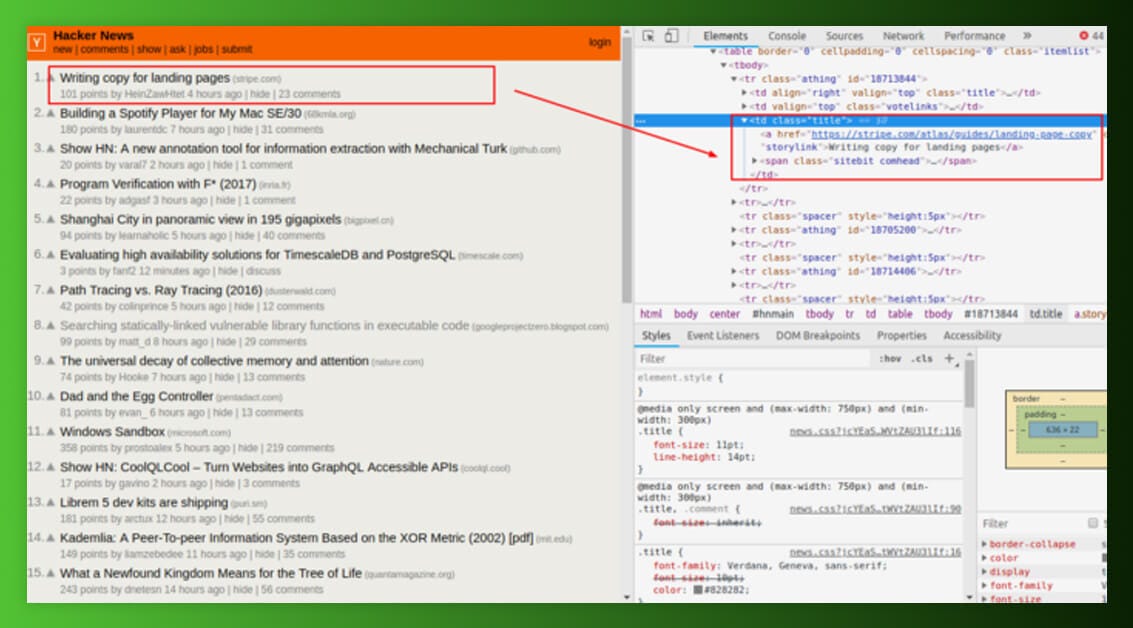
Recopilamos contenido HTML relacionado que encontramos al realizar la solicitud desde navegadores como Chrome. Luego, necesitamos ayuda de Chrome Developer Tools para buscar a través del HTML de la página web y elegir los datos necesarios.
Necesitamos extraer los encabezados de noticias, así como sus enlaces relacionados. Puede ver el HTML de una página web haciendo clic con el botón derecho en una página web y seleccionando “Inspeccionar”.
Analizar con HTML usando Cheerio.js
Cheerio es un jQuery para Node.js, donde utilizamos selectores para elegir las etiquetas del documento HTML. Se tomó prestada una sintaxis de selector de jQuery. Con Chrome DevTools, tenemos que obtener selectores para diferentes titulares de noticias, así como sus enlaces. Agreguemos algunas especias a la comida.
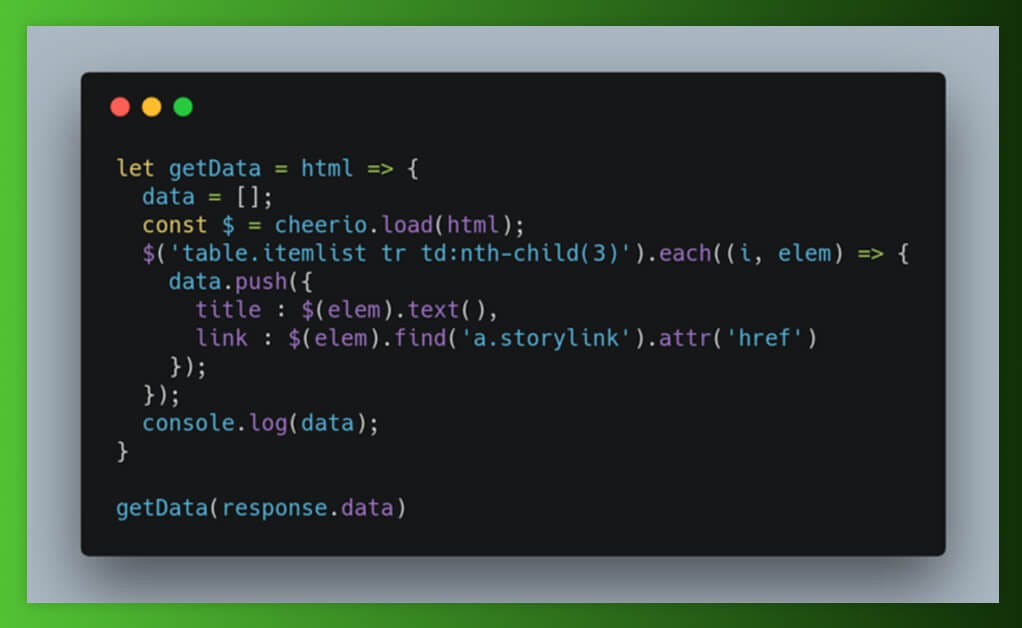
Inicialmente, tenemos que cargar el HTML. El paso en jQuery está implícito ya que jQuery funciona en un DOM compatible. Usando Cheerio, queremos pasar los documentos HTML. Después de cargar un HTML, repetimos todas las incidencias de las filas de la tabla para extraer todas las noticias disponibles en una página.
El resultado aparecerá así:
[
{
title: 'Malaysia seeks $7.5B in reparations from Goldman Sachs (reuters.com)',
link: 'https://www.reuters.com/article/us-malaysia-politics-1mdb-goldman/malaysia-seeks-7-5-billion-in-reparations-from-goldman-sachs-ft-idUSKCN1OK0GU'
},
{
title: 'The World Through the Eyes of the US (pudding.cool)',
link: 'https://pudding.cool/2018/12/countries/'
},
.
.
.
]
Como tenemos toda una serie de objetos de JavaScript que tienen título, así como enlaces de noticias de un sitio de HackerNews. Aquí, podemos extraer datos de diferentes sitios web de gran número. Por lo tanto, nuestra comida se prepara y se ve maravillosa también.
Conclusión
En este blog, inicialmente entendimos qué es el raspado web y cómo podemos utilizarlo para automatizar diferentes operaciones para recopilar datos de diferentes sitios web.
Muchos sitios web están utilizando la arquitectura de aplicación de página única (SPA) para generar contenido dinámicamente para sus sitios web con JavaScript. Obtendríamos una respuesta de las solicitudes HTTP iniciales y no podemos implementar JavaScript para representar contenido dinámico con axios y otros paquetes npm paralelos como solicitudes. Por lo tanto, solo podemos extraer datos de sitios estáticos.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

PHP8: ¡Eche un vistazo a las nuevas funciones!

ALB: 502 respuesta de puerta de enlace incorrecta
