

El libro imprescindible para la ciencia de datos
Aumente su conocimiento e impulse su carrera con esta joya sobre la ciencia de datos.
Ciencia de datos
Introducción
A lo largo de esta publicación, cubriremos una revisión de uno de los mejores libros que debe agregar a su repertorio para aumentar sus habilidades y mejorar su carrera en ciencia de datos.
La ciencia de datos es un campo apasionado y multidisciplinario que involucra algunas de las ciencias más exigentes: desde las matemáticas y la estadística hasta la informática y la programación, terminando con el aprendizaje automático y el análisis de datos y visualización.
El camino del científico de datos atraviesa terrenos complejos y surgen nuevos desafíos y oportunidades a cada paso. Por eso es crucial mantenerse al día y mantener la espada afilada. Es decir, realizar un estudio y aprendizaje constante, tanto de los nuevos trabajos como de las bibliotecas que van surgiendo, como una revisión constante de los fundamentos.
No puedo enfatizar lo suficiente este último punto: los fundamentos son lo más importante que cualquier científico de datos debe dominar. Sobre ellos se construye todo el conocimiento que permite el entrenamiento y despliegue de modelos capaces de predecir con increíble precisión. Pero, una vez que hay una brecha en esos fundamentos, corremos el riesgo de fracasar miserablemente.
Como dice la famosa frase:
“Una cadena es tan fuerte como su eslabón más débil”
Por eso creo firmemente que debemos centrarnos en fortalecer al máximo estos vínculos fundamentales.

Y si hay una disciplina que es la base fundamental de absolutamente todos los componentes que componen la ciencia de datos, es la matemática. Y este será el tema en el que nos centraremos hoy.
Casi todo el mundo odia las matemáticas y huye de ellas a la menor posibilidad. Pero debo decirte que si vas a seguir una carrera en ciencia de datos y quieres tener éxito en ella, definitivamente debes tener un buen conocimiento básico de matemáticas.
Las matemáticas son la base única de cada componente y disciplina que se ajusta a la ciencia de datos: estadística y probabilidad, informática, aprendizaje automático, aprendizaje profundo… Todos ellos son matemáticas aplicadas y debes tener un nivel lo suficientemente decente para comprender cómo surgen todas estas disciplinas. desde. Además, la razón por la que la ciencia de datos y el big data se han disparado en los últimos años es principalmente por el drástico aumento en el poder de cálculo, o en otras palabras, la capacidad de realizar cálculos complejos y largos en menos tiempo.
El aprendizaje automático es una motivación directa y obvia, así como un claro ejemplo de matemáticas aplicadas.
Teniendo esto en cuenta, les he traído hoy una reseña de un gran libro que ha tenido un impacto significativo en la carrera de muchos como científicos de datos y en sus vidas, y que no se puede dejar de recomendar.
Mathematics for Machine Learning
(Matemáticas para el aprendizaje automático)

Este gran libro fue escrito por Marc Peter Deisenroth, A. Aldo Faisal y Chen Soon Ong y publicado el 23 de abril de 2020 y le proporcionará todo lo que necesita para comprender y aplicar con éxito la mayoría de los algoritmos de aprendizaje automático y aprendizaje profundo, optimización. mecanismos, funciones de costos… en orden, todo lo que utilizará a lo largo de su carrera de ciencia de datos.
A medida que mejoran las bibliotecas de software y programación, la mayoría de los profesionales del aprendizaje automático no conocen los detalles técnicos de bajo nivel de los algoritmos. Por lo tanto, existe el peligro de que un profesional desconozca las decisiones de diseño y, por lo tanto, los límites de los algoritmos de aprendizaje automático.
El libro está destinado a ser una guía en las matemáticas que forma la base del aprendizaje automático. Proponen una comprensión del aprendizaje automático como una ciencia que se basa en lo siguiente:
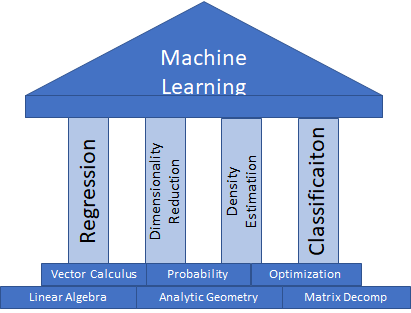
Y así, el libro se divide en dos partes:
Parte 1: Fundamentos matemáticos
En esta parte, el enfoque será establecer una base matemática sólida para construir conceptos de aprendizaje automático más adelante. Los temas específicos cubiertos son:
Linear Algebra / Álgebra lineal
En Machine Learning, los datos se representarán como vectores. Y así, el álgebra lineal será el estudio de esos vectores y matrices.
Analytic Geometry / Geometría analítica
Que tiene como tema central el estudio de la similitud entre vectores.
Matrix Descomposition / Descomposición de matrices
Analizar operaciones en matrices que son extremadamente útiles en el aprendizaje automático, ya que permiten al científico de datos construir una representación intuitiva de los datos, sus transformaciones y cómo realizar un aprendizaje eficiente.
Vector Calculus / Cálculo vectorial
Que permitirá la comprensión de las técnicas de optimización que se utilizan para encontrar los parámetros que maximizarán (o minimizarán) alguna medida de rendimiento, como el Gradient Descent.
Parte 2: Aprendizaje automático
La segunda parte se centrará en los cuatro pilares del aprendizaje automático después de definir matemáticamente los tres componentes del aprendizaje automático (datos, modelos y estimación de parámetros). Estos cuatro pilares son:
Linear Regression / Regresión lineal
Donde el objetivo será encontrar la función que mapeará la entrada a un valor objetivo correspondiente, que normalmente será un número real. Los temas cubiertos son el ajuste de modelos por estimación de parámetros (regresión lineal) y por integración de parámetros (regresión bayesiana).
Dimensionality Reduction / Reducción de dimensionalidad
Utilizando el análisis de componentes principales, el objetivo será encontrar una representación de menor dimensión de los datos de entrada. Esto permitirá un análisis más sencillo. Es importante notar que en estos métodos no hay valores objetivo. La reducción de dimensionalidad pertenece al conjunto de técnicas del denominado Aprendizaje No Supervisado.
Density Estimation / Estimación de densidad
El objetivo será encontrar una distribución de probabilidad que describa los datos de entrada. La atención se centrará en los modelos de mezcla gaussiana para hacer esto y también pertenece al aprendizaje no supervisado.
Classification / Clasificación
De manera similar a la regresión, la clasificación también pertenece al aprendizaje supervisado y se estudia a través de la lente de las máquinas de vectores de soporte. A diferencia de la regresión, los valores objetivo suelen ser números enteros, en lugar de valores reales.
Conclusiones y palabras finales
Si tuviera que resumir este libro en una frase, se vería así:
“La mejor inversión de estudio del año pasado”.
Uno de los mejores valores que aporta este libro es que enlaza mucho los conceptos matemáticos explicados en la primera parte del libro con los algoritmos de Machine Learning detallados en la segunda parte. Si alguna vez tuvo problemas para comprender conceptos como Gradient Descent, no tendrá que preocuparse más por eso después de estudiar Matemáticas para el aprendizaje automático.
No voy a mentir, este es un libro denso y detallado. Tendrá que invertir tiempo y esfuerzo para analizarlo y comprender profundamente sus temas. Pero te aseguro que valdrá la pena. No te rindas, tómate tu tiempo y asegúrate de internalizar sus lecciones. Definitivamente valdrá la pena en su comprensión y aplicación del aprendizaje automático.
Después de leerlo / estudiarlo por primera vez, es una gran herramienta para tener a un lado y le animo a que vuelva a él y actualice los conceptos relacionados cada vez que se enfrente a un desafío de aprendizaje automático. Le dará una gran perspectiva sobre cómo abordar los puntos de bloqueo y definitivamente facilitará su camino a mediano y largo plazo.
Como siempre, espero que haya disfrutado del post y que sepa darle una oportunidad a este increíble libro. Lo puede encontrar en el siguiente enlace:

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Autenticación de usuario: Pasos para agregarlo

UTM: Seguimiento de parámetros para mejor ROI
