

Base de datos de columnas y base de datos de filas: ¿en qué se diferencian?
Queremos que nuestras bases de datos sean rápidas para que las consultas que ejecutamos devuelvan los resultados rápidamente.
Al cambiar la forma en que almacenamos los datos en nuestra base de datos, podemos hacer que la base de datos responda a las consultas y optimizar nuestra base de datos para atender la carga de trabajo analítica o la carga de trabajo transaccional que llamamos OLAP y OLTP.
Las computadoras en general, incluso las bases de datos, leen los datos de discos, discos duros. No estamos hablando de los datos de RAM que se eliminan una vez que se apaga la computadora, sino de los discos duros donde los datos se almacenan de forma permanente.
En estos discos de almacenamiento, los datos se almacenan en forma de bloques. es evidente que si la computadora tiene que leer menos bloques, va a tomar menos tiempo y si la computadora va a leer datos de más bloques, va a tomar más tiempo.
Si los datos que consultamos están en menos bloques, la respuesta de la base de datos sería más rápida.
Entendamos esto con un ejemplo.
Esta es una tabla de ventas de muestra.

Veamos cómo se almacenarán estos datos en un almacén de datos basado en filas.
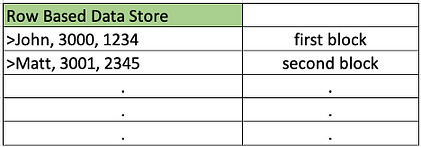
En el formato basado en filas, todo el registro se almacena en un bloque, lo que significa que, como puede ver en la figura, el registro del primer cliente — — – el nombre del cliente, el ID del artículo y el monto de las ventas se almacena en el primer bloque.
Por lo tanto, si buscamos los primeros detalles de los clientes, puede encontrar todo eso en un solo bloque. Este tipo de almacenamiento de datos será excelente para bases de datos transaccionales donde necesitamos los detalles de una sola entidad.
Si tengo que tomar el promedio de todas las ventas, tendría que escanear los cinco bloques de datos, lo que resultaría en más IO y más costos.
Veamos cómo se almacenarán estos datos en un almacén de datos basado en columnas.
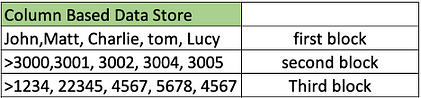
Los datos en las tiendas de columnas se almacenan de manera diferente.
- Aquí las columnas enteras están escritas dentro de un bloque,
- aquí tenemos todos los nombres de los clientes en un bloque,
- todos los IDS de los artículos en el siguiente bloque
- y todo el monto de las ventas en el tercer bloque.
Entonces, en lugar de tener los datos de cada cliente juntos, tenemos toda la columna de datos juntos.
Si quiero acceder a la suma o el promedio de todas las ventas, esta base de datos sería rápida porque todo se guardaría en un solo bloque.
Usaré este tipo de base de datos para consultas analíticas como sumas o promedios, etc.
La base de datos en columnas también es muy adecuada para la compresión porque cada bloque tendrá el mismo tipo de datos, ya sean números o cadenas, etc., por lo que sería muy fácil comprimir los datos en el bloque de manera eficiente.
¿Cómo funcionarían las consultas con estos diferentes métodos de almacenamiento?
Consulta de estilo transaccional
P.ej:
SELECT Customer_name , Sales
FROM data
WHERE Item_ID=3000
Esta es una consulta de estilo transaccional donde necesitamos todos los detalles de una persona.
En la base de datos de filas, necesitamos escanear los datos de un solo bloque, mientras que en la base de datos de columnas tendríamos que escanear muchos bloques.
Consulta de estilo analítico
P.ej:
SELECT Item_ID, count(1)
FROM data
GROUP BY Item_ID
Aquí queremos contar cuántas observaciones tenemos de cada Item_ID, lo que podría hacerse leyendo un solo bloque en la base de datos Columnar, mientras que en la base de datos de filas tendríamos que escanear todos los bloques.
Gracias por llegar hasta aquí, si encuentras esto útil no olvides dejar un👍🏼y suscribirse para recibir más contenido.
Si le interesa, puede echar un vistazo a algunos de los otros artículos que he escrito recientemente sobre Node.js y AWS Lambda:

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post
Las 9 cosas que las personas exitosas comienzan a hacer temprano en la vida

Extensiones de Chrome para desarrolladores
