

Compresión de activos y Cloudfront
¿Cómo podemos lograr una compresión de activos con Cloudfront?
Background
En Bolt se toman la velocidad muy en serio. Es clave para brindarles a los clientes y usuarios la mejor experiencia de pago posible.
Entonces, cuando uno de nuestros comerciantes nos hizo ping en octubre de 2019 diciendo que nuestros activos de front-end estaban tardando varios segundos en cargarse, estábamos muy preocupados.
Usaban Cloudfront (AWS CDN) para atender nuestros activos estáticos desde ubicaciones cercanas a los usuarios. Así que estaban confundidos por qué las velocidades de carga seguían siendo lentas. Y obviamente, como es el caso de los errores duros, no pudieron reproducir el problema.
Problema
Le pidieron algunas capturas de pantalla a la persona que informó el problema. Ese fue un gran punto de partida. Resulta que a veces estaban sirviendo activos sin comprimir. Leyó correctamente, no gzip o Brotli, solo js sin comprimir, que era más grande en ~3x.
Pasaron algún tiempo escribiendo scripts para ver con qué frecuencia sucedía esto y en sus pruebas, 2 de cada 100 solicitudes en la región que estaban probando a partir de activos servidos sin comprimir. Sin embargo, en algunas otras áreas del mundo, ese número subió a ~15 de cada 100 solicitudes. Usaron el servicio de compresión automática de Cloudfront, pero después de mucha lectura y algunos tickets de soporte, descubrieron que la compresión automática de Cloudfront era un servicio de máximo esfuerzo. Necesitaban algo más confiable.
Necesitaban encontrar una nueva solución con solo 5 semanas antes de la semana más importante en compras en línea: Black Friday.
Solución
Se les ocurrió una solución que era mejor que gzip y admitía Brotli (que Cloudfront no admitía en ese entonces). Esto les dio una mejora automática de entre un 14% y un 20% con respecto a gzip.
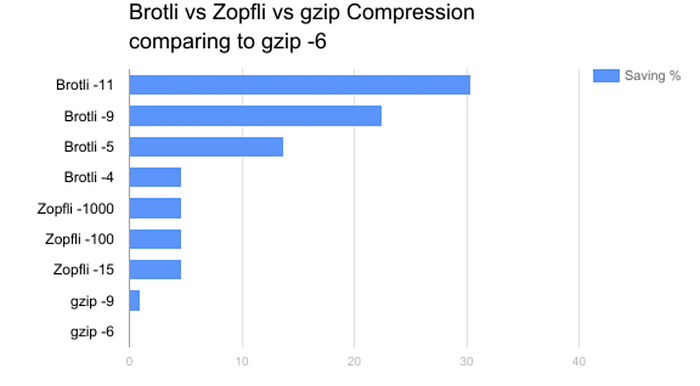
Simplemente precomprimieron todos los activos en su tubería de compilación, agregando soporte para gzip y Brotli, y cuando sirvieron a través de Cloudfront, devolvieron el activo correcto según la compatibilidad del navegador del usuario.
Cada solicitud de un navegador moderno agrega un encabezado de aceptación de codificación, que especifica los tipos de compresión que el navegador puede admitir. Cloudfront le permite redirigir una solicitud a través de cualquiera de las cuatro lambdas de borde. La lambda de borde de solicitud de origen era lo que querían.
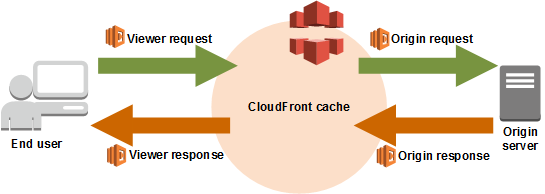
Luego hicieron una lambda simple que devolvió activos comprimidos de Brotli o activos comprimidos con gzip, según el navegador.
const acceptEncoding = headers["accept-encoding"] || [];
if (acceptEncoding.findIndex(v => v.value.includes("br")) >= 0) {
request.uri += ".br";
}
if (acceptEncoding.findIndex(v => v.value.includes("gz")) >= 0) {
request.uri += ".gz";
}
Entonces, ¿por qué una solicitud de origen y no una solicitud de espectador? Bueno, eligieron almacenar en caché en Cloudfront en función de la codificación de aceptación, por lo que de esta manera, Cloudfront realizó una solicitud al origen para cada tipo de compresión. Hacer esto a pedido del espectador significaría que estarían accediendo a su origen para todas y cada una de las solicitudes del usuario.
Lograron implementar esto en ~1.5 semanas y, por supuesto, no volvieron a aparecer más errores de este tipo. Estaban sirviendo activos comprimidos de Brotli. ¡Hasta que alguien de Pied Piper lance el algoritmo de compresión intermedio, probablemente estarán en un buen lugar!
Desde entonces, Cloudfront ha agregado soporte para Brotli, sin embargo, tenga en cuenta que su compresión aún se realiza con el mejor esfuerzo, y cuando tienen mucho tráfico, sus usuarios sufren.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

TypeScriptFunction: Centralice sus errores

AWS de Amazon: Alojamiento de un sitio web estático
