

Paralelismo con el multiprocesamiento de Python
Multiprocesamiento — Una de las cosas más difíciles que puede enfrentar un desarrollador es hacer que su código se ejecute más rápido (más). El problema es que muchas tareas tardan en procesarse, incluso en equipos rápidos con varios núcleos.
En parte, esto sucede debido a Python GIL (Python Global Interpreter Lock) que permite que solo un subproceso tome el control sobre Python Interpreter, por lo que nunca termina usando todo el poder de la máquina simplemente ejecutando una función o método.
¡Pero no se preocupe! Puede ocuparse de eso.
Imagine que tiene que ejecutar una función 3 veces y cada resultado devuelto compone un resultado final. Obviamente, en aras de la simplicidad, en esta publicación, los de aquí serán simples for loops que sumarán n a todos los n anteriores en un rango.
Sin multiprocesamiento (1 min y 30 s):
from datetime import datetimestart = datetime.now() def loop(r): for n in range(r): result = (n*(n+1))/2 return resultranges = [100000000, 200000000, 300000000] results = []if __name__ == '__main__': for r in ranges: results.append(loop(r)) print(f’Result: {sum(results)}’) print(f’Time spent: {datetime.now() - start}')>>> Result: 6.99999997e+16 >>> Time spent: 0:01:30.659429
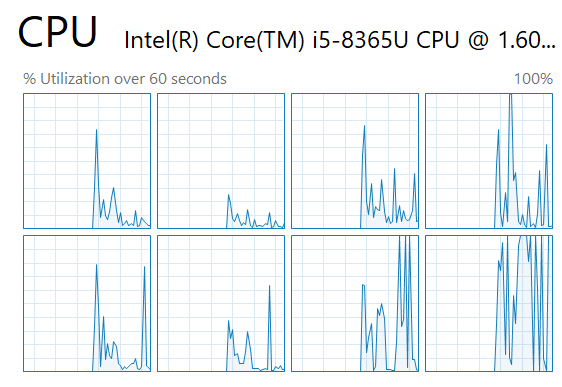
Ahora el siguiente paso es instalar la biblioteca psutil que nos permite establecer un núcleo específico para cada instancia de nuestra función.
Usando multiprocesamiento y psutil de forma asincrónica (0 min y 53 s):
from datetime import datetime import multiprocessing as mp import psutilstart = datetime.now() def loop(core, r): proc = psutil.Process() proc.cpu_affinity([core]) for n in range(r): result = (n*(n+1))/2 return resultcores = [0, 1, 2] ranges = [100000000, 200000000, 300000000] results = []if __name__ == '__main__': with mp.Pool() as pool: for core in cores: p = pool.apply_async(func=loop, args=(core, ranges[core],)) results.append(p) pool.close() pool.join() result = 0for p in results: result = result + p.get() print(f’Result: {result}’) print(f’Time spent: {datetime.now() - start}')>>> Result: 6.99999997e+16 >>> Time spent: 0:00:53.664461
Como puede ver a continuación, se están utilizando 3 núcleos al mismo tiempo y pudimos obtener una reducción de tiempo de aproximadamente un 41%, que eventualmente aumenta si está haciendo cálculos más pesados o cargando grandes conjuntos de datos en Pandas, por ejemplo.
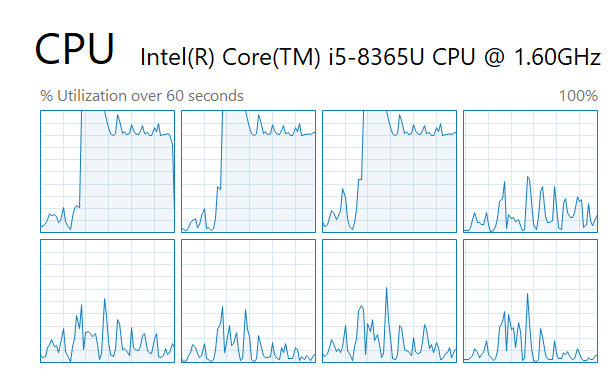
¿Es posible reducir aún más el tiempo de procesamiento? Sí, es posible, pero eso quedará para otra publicación.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Eliminación en cascada para GraphQL

setTimeout () vs setImmediate () Timer en Node.js
