

Depuración de registros de AWS Lambda 101
Depuración — La informática sin servidor, en particular AWS Lambda, está ganando un tremendo impulso para crear aplicaciones sin servidor.
Una de las principales razones es la rápida reducción de los costos de desarrollo. Por ejemplo, para la mayoría de los escenarios, pagar por invocación ayuda a reducir enormemente los costos operativos, en lugar de implementar y ejecutar aplicaciones en una arquitectura basada en servidor.
Incluso si son máquinas virtuales de bajo costo (por ejemplo, Amazon EC2). Agregue a eso, una menor dependencia del personal o los mecanismos de soporte, ¡porque ahora no tiene que administrar o monitorear servidores! Serverless es el camino a seguir, ¡y nada menos que mágico!
Pero, ¿el desarrollo de aplicaciones en la infraestructura sin servidor es todo pan comido?
La mayoría de las veces, sí. Excepto, cuando las Lambdas se encuentran con miles o millones, y uno comienza a experimentar errores.
¿Por qué fallarían? Bueno, las razones pueden ser muchas. Aquí hay algunos (no limitados a):
- Las llamadas API dependientes devuelven respuestas malas o incorrectas, o no devuelven datos, lo que hace que se agote el tiempo de espera de una función de Lambda
- Manejo incorrecto de casos extremos
- Tiempos de espera de conexión de base de datos
- Excepciones no controladas, por nombrar algunas
- El uso de la consola de AWS para hacer depuración de funciones puede ser un proceso largo y engorroso.
Echemos un breve vistazo a ese flujo de trabajo:
- Utilice la consola de CloudWatch para identificar manualmente la hora a la que se produjo el error.
- Cambie a los registros de CloudWatch e identifique el grupo de registros al que pertenece la función. Luego, haga clic en Buscar eventos
- Juega con la fecha y la hora en que ocurrió el error
- Use búsquedas de palabras clave que crea que podría contener el error en cuestión
- Comienza tu búsqueda
Es importante tener en cuenta aquí que la mayoría de los pasos anteriores implican una buena cantidad de conjeturas y estimaciones.
La mayoría de las veces, es posible que los resultados de su búsqueda no contengan el error que está buscando. A menos que tenga la suerte de escribir “error” y el resultado solo muestre lo que está buscando.
De todos modos, aquí hay una captura de pantalla de los resultados, incluso cuando uno tiene la suerte de encontrar los errores de una sola vez.

Como es de suponer, hay muy poco contexto que se puede obtener de estos resultados, excepto que tiene el nombre del flujo de registro y la marca de tiempo.
Ahí es cuando el desarrollador cambia a otra pantalla para encontrar el flujo de registro específico, para ver y comprender el contexto.
La pregunta es si vale la pena invertir (si podemos llamarlo así) tanto tiempo en la identificación de errores y resolverlos.
Claramente, ya no. Habiendo repasado este tedioso proceso muchas veces, encontramos algunas herramientas que potencialmente podrían automatizarlo. Pero pocos ofrecieron soluciones económicas y no invasivas.
KloudMate nació como resultado de muchas salidas de este tipo por parte de nuestros propios desarrolladores.
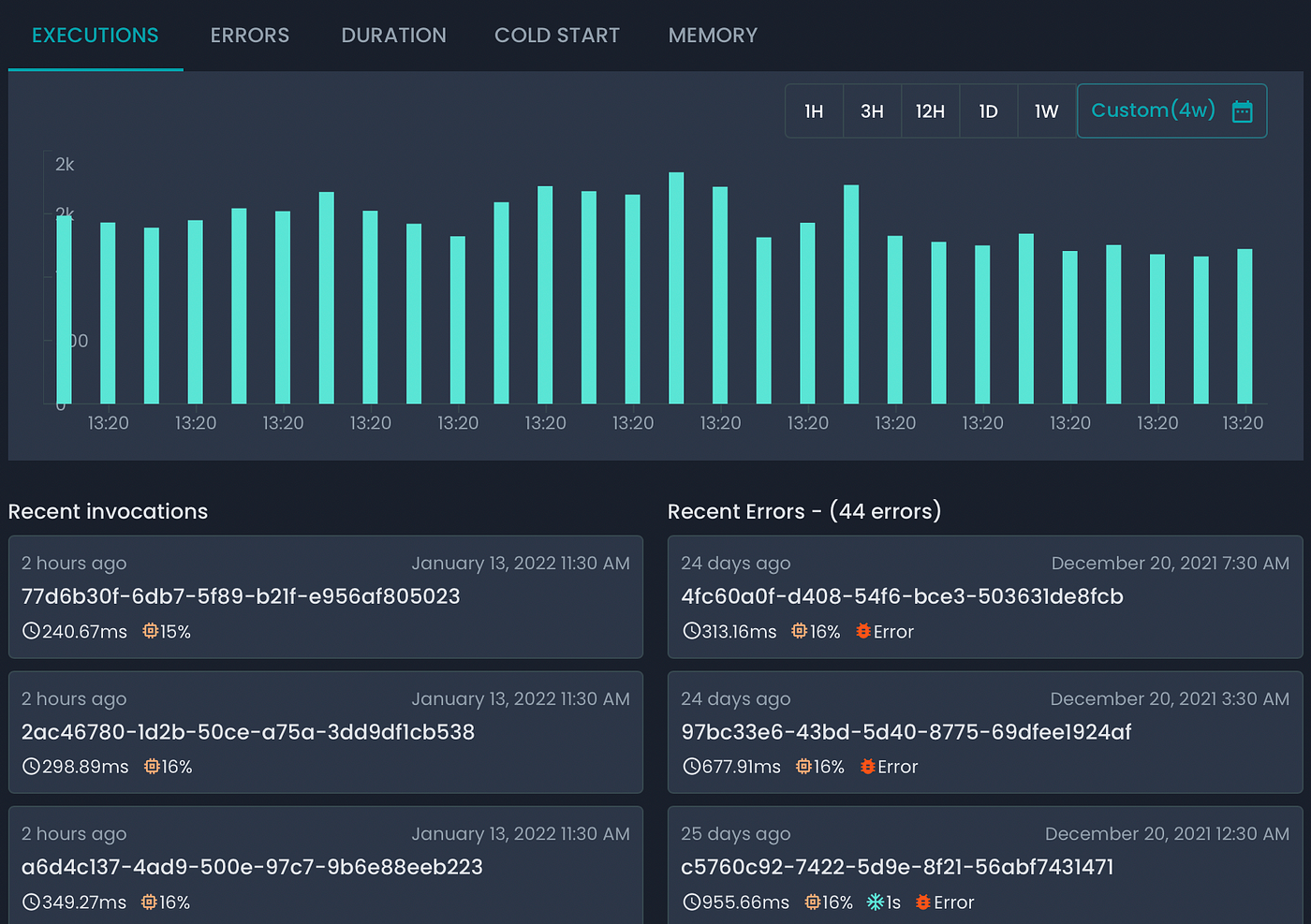
Los beneficios de usar plataformas como KloudMate pueden ser numerosos:
- ¡Conecte su cuenta de AWS en menos de 2 minutos! Sin cambio de código, sin instalación de agente en absoluto
- Reduzca drásticamente el tiempo necesario para identificar errores y fallas en medio de millones de invocaciones de lambda
- Vea las métricas que importan sin conjeturas ni tiempo de configuración: duración de la ejecución, memoria utilizada, duración del arranque en frío, gravedad, etc.
- Registro de texto completo Busque y filtre millones de registros para encontrar exactamente lo que está buscando en segundos
- En efecto, mejore el estado de Observabilidad de su aplicación e infraestructura Serverless
¡Esto es todo sobre depuración!
Actualmente en versión beta, los desarrolladores y usuarios pueden solicitar acceso anticipado de forma gratuita en el sitio web de KloudMate.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Proyecto de Nodejs: Cómo crearlo con EJS+TS

AWS Athena: Consulta de registro CloudFront y WAF
