

Laravel: evitando “quién almacena en caché primero”
Les contaré una historia de varios procesos que almacenan en caché lo mismo, una y otra vez…
Supongamos que nos toca crear un proyecto para un cliente que escala de uno a alrededor de 5 ~ 10 procesos al mismo tiempo. Estos tienen que hacer una consulta compleja basada en el resultado de una API externa, que es lenta y detiene todos los procesos.
Como es lógico, guardermos el resultado en caché. ¿El problema? Los procesos aún se estancan durante varios segundos. ¿No funciona el caché?
El problema no es el caché en sí, sino el procedimiento. Dado que estos procesos pueden comenzar a solo milisegundos de distancia entre sí, todos ellos perderán el caché hasta que se llene. En otras palabras, todos los procesos ejecutarían la misma solicitud HTTP y la misma consulta y la guardarían en la caché.
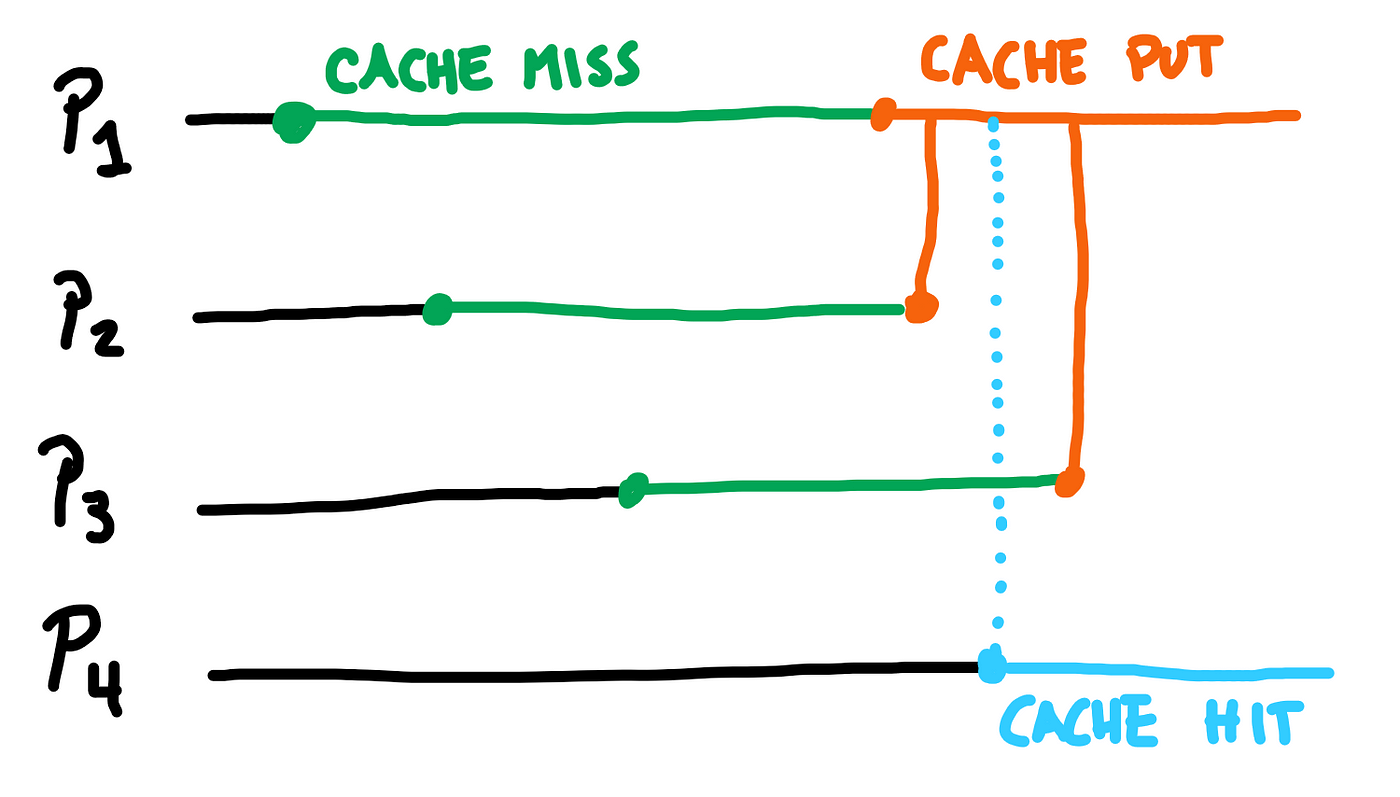
Afortunadamente para nosotros, Laravel tiene bloqueos “atómicos” para el manejo de la caché, que ayudarían a solucionar este problema.
Bloqueando para mí, desbloqueado para todos los demás
El caché en Laravel, siempre que su controlador lo admita, contiene un sistema de “bloqueo”. Lo que hace es muy simple: cuando establece un valor como bloqueado, devuelve true.

¿Por qué devuelve un booleano? Porque si lo vuelves a llamar, recibirás false porque ya está bloqueado.
También puede liberar el bloqueo. Esto permitirá que el valor sea bloqueado nuevamente por cualquier otra persona, como otro proceso.

La lógica anterior se puede replicar con cualquier cosa, pero hay un buen truco para usar este bloqueo: puede “esperar” a que alguien lo libere, o “fallar” si cree que ha esperado lo suficiente, en lugar de simplemente sondear sin procesar el caché como si no hubiera un mañana.
Para hacer esto, podemos usar el método block(), que acepta una devolución de llamada para ejecutar una vez que se ha adquirido el bloqueo.

Podemos usar esto a nuestro favor para evitar que múltiples procesos almacenen en caché los mismos datos, dejando solo que el primero lo haga mientras los otros procesos esperan hasta que se almacenen, en lugar de llenar el servidor con carga para un resultado que será el mismo.
Uno almacena en caché, el resto espera
La lógica de esto es realmente simple:
- Adquiriremos el candado por un valor determinado y, una vez adquirido,
- comprobaremos si la caché tiene los datos para devolver,
- de lo contrario, recuperaremos los datos y los almacenaremos en la caché.
El primer paso se puede reanudar usando block(), que acepta una devolución de llamada para ejecutar si el bloqueo se adquiere antes de que se agote el tiempo de espera.
El segundo y tercer pasos son básicamente el método remember(), que verifica si los datos de la caché existen, o ejecuta una devolución de llamada para recuperar y almacenar los datos, devolviéndolos al desarrollador.
Resumiendo todo, terminamos con algo como esto:

Esta función mata dos pájaros de un tiro:
- El primer proceso que adquiera el bloqueo ejecutará la devolución de llamada, que recuperará y almacenará los datos.
- El siguiente proceso esperará para adquirir el bloqueo y, una vez hecho,
remember()devolverá los datos almacenados en caché.
Este parece ser un caso límite que se debe incluir en el marco, pero para almacenar en caché datos que son computacionalmente costosos (una consulta SQL compleja) o gravosos (una solicitud HTTP lenta), es posible que desee evitar que varios procesos hagan lo mismo.

Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.
Recent Post

Jobs: La observación más importante que cambió Apple

Revisión de código: Mejore su nivel
