
[vc_row el_class=”blog-info”][vc_column][vc_single_image source=”featured_image” img_size=”full” style=”vc_box_rounded”][vc_empty_space height=”40px”][vc_row_inner][vc_column_inner width=”1/6″][/vc_column_inner][vc_column_inner width=”2/3″][vc_column_text el_class=”font-weight-bold”]
Descomprimir y Gzip archivos S3 entrantes con AWS Lambda
Gzip y Descomprimir – Más fácil, más rápido y mejor…
[/vc_column_text][vc_empty_space height=”40px”][/vc_column_inner][vc_column_inner width=”1/6″][/vc_column_inner][/vc_row_inner][vc_row_inner][vc_column_inner width=”1/6″][/vc_column_inner][vc_column_inner width=”2/3″][vc_column_text]
Hace un tiempo me encontré con un escenario en el que los archivos S3 entrantes estaban comprimidos. Cada archivo comprimido contenía cinco archivos de texto o CSV. Sin embargo, para su posterior procesamiento, necesitaba extraer el contenido comprimido y convertirlo al formato comprimido con Gzip. Dado que hubo una gran afluencia de archivos, no parecía posible descomprimir y gzipear manualmente.
Automatización
La mejor manera de automatizar el proceso parecía utilizar las funciones de AWS Lambda. Si se dirige a la pestaña Propiedades de su depósito S3, puede configurar una Notificación de evento para todos los eventos de “creación” de objetos (o solo eventos PutObject). Como destino, puede seleccionar la función Lambda donde escribirá su código para descomprimir y gzip archivos.
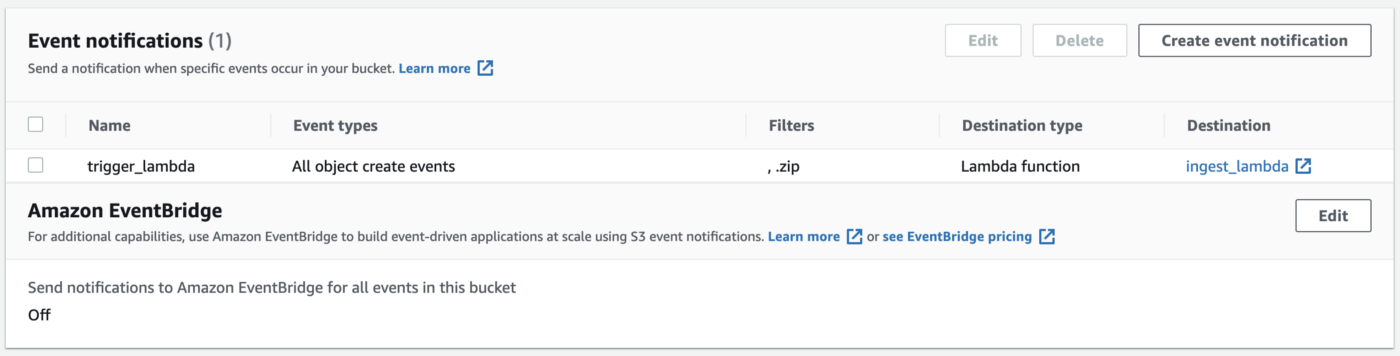
Ahora, cada vez que se agregue un nuevo archivo .zip a su depósito S3, se activará la función lambda. También puede agregar un prefijo a la configuración de notificación de eventos, por ejemplo, si solo desea ejecutar la función lambda cuando los archivos se cargan en una carpeta específica dentro del depósito S3.
La función lambda puede verse así:
import logging
import zipfile
from io import BytesIO
from boto3 import resource
import gzip
import io
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def unzip_and_gzip_files(filekey, sourcebucketname, destinationbucket):
try:
zipped_file = s3_resource.Object(bucket_name=sourcebucketname, key=filekey)
buffer = BytesIO(zipped_file.get()["Body"].read())
zipped = zipfile.ZipFile(buffer)
for file in zipped.namelist():
logger.info(f'current file in zipfile: {file}')
final_file_path = file + '.gzip'
with zipped.open(file, "r") as f_in:
gzipped_content = gzip.compress(f_in.read())
destinationbucket.upload_fileobj(io.BytesIO(gzipped_content),
final_file_path,
ExtraArgs={"ContentType": "text/plain"}
)
except Exception as e:
logger.info(f'Error: Unable to gzip & upload file: {e}')
def lambda_handler(event, context):
global s3_resource
s3_resource = resource('s3')
sourcebucketname = 'incoming-bucket'
destination_bucket = s3_resource.Bucket('final-bucket')
key = event['Records'][0]['s3']['object']['key']
unzip_and_gzip_files(key, sourcebucketname, destination_bucket)
return {
'statusCode': 200
}
Cuando un evento activa esta función lambda, la función extraerá la clave de archivo que provocó la activación. Usando la clave de archivo, cargaremos el archivo zip entrante en un búfer, lo descomprimiremos y leeremos cada archivo individualmente.
Dentro del ciclo, cada archivo individual dentro de la carpeta comprimida se comprimirá por separado en un archivo de formato gzip y luego se cargará en el depósito S3 de destino.
Puede actualizar el parámetro final_file_path si desea cargar los archivos en una carpeta específica. De manera similar, puede actualizar parámetros como sourcebucketname y destination_bucket según sus requisitos. También puede cargar los archivos comprimidos con gzip en el mismo depósito de origen.
Otra forma de hacer lo mismo podría ser leer primero el archivo S3 en la carpeta /tmp y luego descomprimirlo para su posterior procesamiento. Sin embargo, este método puede bloquearse si comienza a recibir varios archivos en su depósito S3 al mismo tiempo.
Configuración lambda
Tenga en cuenta que, de manera predeterminada, Lambda tiene un tiempo de espera de tres segundos y una memoria de solo 128 MB. Si tiene varios archivos en su depósito S3, debe cambiar estos parámetros a sus valores máximos:
- Tiempo de espera = 900
- Tamaño_memoria = 10240
Permisos de AWS
El rol de AWS que está utilizando para ejecutar su función Lambda requerirá ciertos permisos. En primer lugar, requeriría acceso a S3 para leer y escribir archivos. Las siguientes políticas son las principales:
“s3: ListBucket”
“s3:ObjetoCabeza”
“s3:ObtenerObjeto”
“s3:ObtenerVersiónObjeto”
“s3:PonerObjeto”
También debe tener acceso a CloudWatch para poder iniciar sesión y depurar su código si es necesario.
“registros: Crear grupo de registros”
“registros: Crear flujo de registro”
“registros:PutLogEvents”
La replicación de un flujo de trabajo similar a través de Terraform también es bastante sencilla.
[/vc_column_text][/vc_column_inner][vc_column_inner width=”1/6″][/vc_column_inner][/vc_row_inner][/vc_column][/vc_row][vc_row el_class=”social-info”][vc_column width=”1/6″][/vc_column][vc_column width=”2/3″][vc_row_inner][vc_column_inner width=”1/2″][vc_column_text][social_share_button themes=’theme1′][/vc_column_text][/vc_column_inner][vc_column_inner el_class=”youtube-inner-col” width=”1/2″][vc_column_text][likebtn theme=”youtube” lang=”auto” show_like_label=”0″ white_label=”1″ alignment=”right”][/vc_column_text][/vc_column_inner][/vc_row_inner][vc_row_inner el_class=”social-info-inner”][vc_column_inner width=”1/4″][vc_single_image image=”921″][/vc_column_inner][vc_column_inner width=”3/4″][vc_column_text]
Diego Pacheco
Ingeniero en Sitemas, MBA (Babson College). Desarrollador PHP/Java/JavaScript. Fundador & CEO de EpicStudio. Entusiasta de las tecnologías web (JavaScript, Vue, Laravel, AWS, Docker) Viajes, Negocios, Surf y Growth.[/vc_column_text][asvc_list_item icon_fontawesome=”fa fa-calendar-o” icon_size=”14px”]Programar una reunión[/asvc_list_item][/vc_column_inner][/vc_row_inner][/vc_column][vc_column width=”1/6″][/vc_column][/vc_row][vc_row][vc_column][vc_column_text]
Recent Post
[/vc_column_text][lvca_posts_carousel posts_query=”size:3|order_by:rand|post_type:post” image_linkable=”true” image_size=”full” taxonomy_chosen=”post_tag” display_title=”true” display_post_date=”true” display_summary=”true” autoplay_speed=”3000″ animation_speed=”300″ display_columns=”3″ scroll_columns=”3″ gutter=”3″ tablet_display_columns=”2″ tablet_scroll_columns=”2″ tablet_gutter=”3″ tablet_width=”800″ mobile_display_columns=”1″ mobile_scroll_columns=”1″ mobile_gutter=”3″ mobile_width=”480″][vc_empty_space height=”20px”][/vc_column][/vc_row]